
Чому створення Robots.txt є важливим
Створення файлу robots.txt виявляється ключовим компонентом для ефективного керування індексуванням і забезпечення безпеки в онлайн-середовищі. У цій статті ми розглянемо важливі аспекти створення та використання цього текстового файлу, який повідомляє пошуковим системам, як вони повинні взаємодіяти з вашим веб-сайтом.





Використання файлу robots.txt
Ми розкриємо, як створення цього файлу дозволяє вам впливати на індексацію веб-сайту, контролюючи, які частини повинні бути видимими для пошукових систем, а які – ні. Також ви дізнаєтеся, як за допомогою robots.txt можна зменшити навантаження на сервер та оптимізувати використання ресурсів, вказуючи пошуковим системам, які частини сайту можна ігнорувати. На прикладах ми розглянемо, як використання файлу robots.txt може бути важливим інструментом для запобігання надмірного трафіку та збереження пропускної здатності вашого сервера.
Що таке Robots.txt
Robots.txt – текстовий файл, який впроваджується до кореневої директорії домену, що надає інструкції роботам пошукових систем щодо сканування сторінок вашого веб-сайту. На практиці файли robots.txt повідомляють веб-павукам, чи можуть вони сканувати певні папки на веб-сайті. Ці інструкції щодо сканування визначаються за допомогою «заборони» або «дозволу» доступу всім або жодному або певним сканерам.
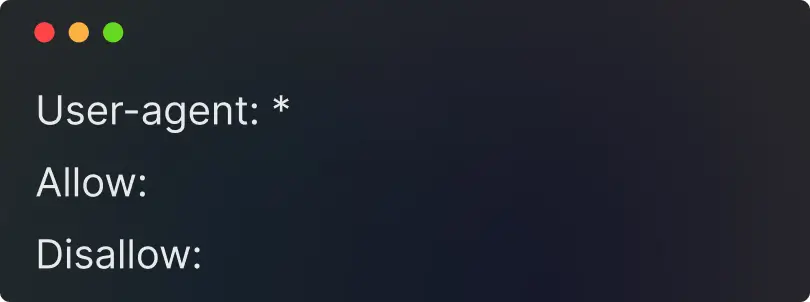
Створення текстового файлу Robots.txt
Створити файл robots.txt легко, вам просто потрібно знати кілька конкретних команд.
- Ви можете створити цей файл за допомогою блокнота свого комп’ютера або будь-якого іншого текстового редактора, який вам подобається.
- Вам також потрібно мати доступ до кореневої папки вашого домену, оскільки саме там ви повинні зберегти створений файл.
- Щоб створити файл robots.txt, вам потрібно увійти в кореневу папку свого домену та зберегти файл там.
Ключові вимоги до файлу Robots.txt
- Для кожного веб-сайту має бути один файл robots.txt.
- Щоб файл robots був знайдений, завжди додавайте його до свого домашнього каталогу або кореневого домену.
- Кожен піддомен кореневого домену використовує різні файли robots.txt. Це означає, що і blog.example.com, і example.com повинні мати власні файли robots.txt (blog.example.com/robots.txt і example.com/robots.txt).
- У файлі robots.txt враховується регістр: файл має називатися “robots.txt” (а не Robots.txt, файл robots.TXT або ще щось).
- Файл складатиметься з різних директив, згрупованих за роботою, до якого вони застосовуються. Крім того, у кожній групі політик не може бути порожніх рядків. Також зважимо, що кожна група директив починається з поля user-agent, яке, до речі, служить для ідентифікації робота, до якого належать зазначені директиви.
- Деякі користувачі (роботи) можуть ігнорувати файл robots.txt. Це особливо притаманно менш етичних трекерів, таких як шкідливі боти або програми для очищення адрес електронної пошти.
- Файл robots.txt загальнодоступний: просто додайте /robots.txt до кінця будь-якого кореневого домену, щоб переглянути політики для цього веб-сайту. Це означає, що будь-хто може бачити, які сторінки ви хочете або не хочете відстежувати, тому не використовуйте їх для приховування особистої інформації користувача.
- Зазвичай рекомендується вказувати розташування будь-якої карти сайту, пов’язаної з цим доменом, у нижній частині файлу robots.txt.
Синтаксис і директиви robots.txt
Синтаксис дуже простий:
- Ви призначаєте правила для ботів, вказуючи їхній агент користувача (бот пошукової системи), а потім директиви (правила).
- Ви також можете використовувати символ зірочки (*), щоб призначити директиви будь-якому агенту користувача. Це означає, що дане правило стосується всіх ботів, а не конкретного.
Символи файлу robots.txt
Існує п’ять загальних термінів, які ви, ймовірно, зустрінете у файлі robots:
User-agents (агенти користувачів). Вказує назву конкретного веб-сканера, якому ви надаєте інструкції щодо сканування.
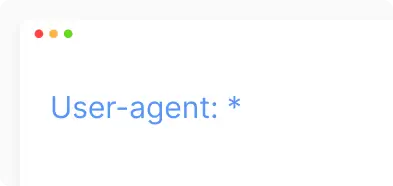
- Застосовується до всіх пошукових ботів без винятку.
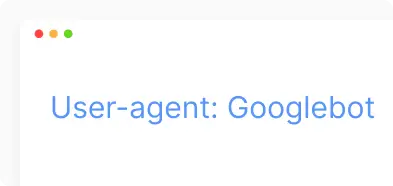
- Застосовується конкретно до Googlebot або інших визначених ботів.
Disallow robots.txt (заборонити). Команда, яка використовується для вказівки агенту користувача не сканувати дану URL-адресу. Для кожної URL-адреси дозволено лише один рядок «Disallow:».
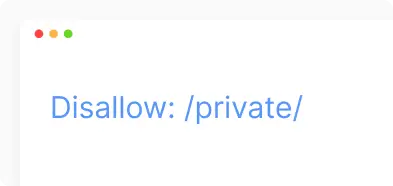
- Заборона доступу до конкретної папки або сторінки.
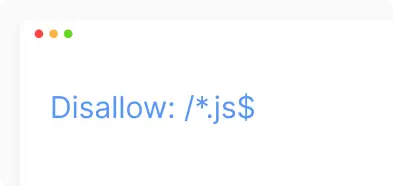
- Вказує пошуковим ботам, що всі файли з розширенням «.js» у шляхах сайту не повинні бути індексовані.
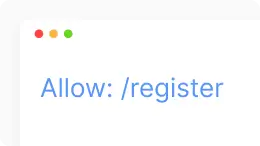
Allow robots.txt (дозволити). Застосовується лише для Googlebot. Ця команда повідомляє Googlebot, що він може отримати доступ до сторінки чи вкладеної папки, навіть якщо її вкладену папку вимкнено.
Crawl-delay robots.txt (затримка сканування). Кількість секунд, яку сканер повинен чекати перед завантаженням і скануванням вмісту сторінки. Зверніть увагу, що Googlebot не розпізнає цю команду, але швидкість сканування можна налаштувати в Google Search Console.

- Це означає, що роботи повинні чекати 30 секунд між кожним доступом.
Robots.txt Sitemap. Використовується для виклику розташування будь-якої XML карти сайту, пов’язаної з цією URL-адресою. Зверніть увагу, що ця команда підтримується лише Google, Ask, Bing і Yahoo.

Підвищте видимість вашого бізнесу:
SEO-рішення для росту!
Що потрібно закривати в robots.txt
Файл robots використовується для передачі директив пошуковим системам щодо областей веб-сайту, які слід виключити зі сканування чи індексації. Ось кілька прикладів того, що може бути заборонено у файлі robots.txt:
- Конфіденційні або приватні каталоги: Ця директива запобігає доступу пошукових систем до “private” каталогу веб-сайту, який може містити чутливу або конфіденційну інформацію.
- Конфігураційні файли або конфіденційні дані: Якщо є такі файли, бажано заборонити пошуковим системам доступ до них.
- Динамічні ресурси: якщо є тимчасові ресурси або динамічно створені сторінки, які не є ключовими для індексації, ви можете виключити їх із пошукових систем.
- Тестові версії або версії для розробки: якщо на веб-сайті є версії, які використовуються лише для тестування чи розробки, бажано виключити їх із пошукових систем.
- Розділи, які генерують марний трафік: якщо є частини сайту, які генерують марний трафік або не мають відношення до пошукових систем, їх також можна закрити.
Приклади використання файлу Robots.txt
Приклад robots.txt 1. Пошукові системи можуть просканувати весь ваш сайт
Є кілька способів повідомити пошуковим системам, що вони можуть просканувати весь ваш сайт. Ви можете використовувати цей синтаксис:

Або ви можете залишити файл robots.txt порожнім (або не мати його взагалі).
Приклад robots.txt 2. Заборонити Google сканувати ваш сайт
У цьому прикладі лише Google не зможе просканувати сайт, тоді як усі інші пошукові системи зможуть це зробити:

Зауважте, що якщо ви не дозволите роботу Googlebot, така ж заборона застосовуватиметься до всіх роботів Google. Наприклад, також для сканера Google News (googlebot‑news) або Google Images (googlebot‑images).
Приклад robots.txt 3. Заборонити сканування певного файлу
У цьому прикладі жодна пошукова система не може сканувати PDF-файл «about-robotstxt.pdf», який міститься в папці «pdf»:

Як перевірити файл robots.txt
Перевірка файлу robots.txt може бути важливим етапом в оптимізації індексації вашого веб-сайту пошуковими системами. Існує кілька способів це зробити:
- Відкрийте ваш браузер і введіть URL вашого веб-сайту, додаючи /robots.txt в кінець (наприклад, http://example.com/robots.txt).
- Ви побачите текстовий вміст вашого файлу robots.txt. Перевірте, чи відображаються правила так, як ви очікуєте.
- У власному обліковому записі Google для веб-майстрів (Google Search Console), ви можете перевірити розділ “Покриття” і обрати “Файл robots.txt”.
- Тут ви побачите статус вашого файлу robots.txt та будь-які проблеми, які можуть впливати на індексацію.
- В браузерах Chrome або Firefox ви можете використовувати вбудовані інструменти для розробників. У вкладці “Network” ви знайдете можливість перегляду файлу robots.txt.
- Просто введіть в адресному рядку chrome://net-internals/#hsts (для Chrome) або about:config (для Firefox) і введіть robots.txt в розділі “Location”.
- Існують онлайн-інструменти, такі як “Google Robots.txt Tester”, які дозволяють вам перевірити файл robots.txt на наявність помилок та правильність вказаних правил.
Переконайтеся, що ваш файл robots містить правильні директиви і не містить помилок, щоб забезпечити ефективне управління індексацією вашого веб-сайту.
Підсумок
Robots.txt — простий, але дуже потужний файл. Використовувати його свідомо означає покращувати оптимізацію та позиціонування в пошукових системах. Однак його використання без знань може завдати серйозної шкоди органічній видимості сайту.
Вам також може сподобатися

Що таке юзабіліті тестування та який вид краще обрати
Юзабіліті тестування - це методологія, яка використовується для оцінки зручності використання веб-сайту та покращення користувацького досвіду. Це процес...

Типові помилки SEO просування і способи їх виправлення
SEO помилки можуть негативно вплинути на успішність сайту та рівень конверсії. Необхідно ознайомитись з найбільш розповсюдженими

Як використовувати візуальний контент для залучення аудиторії?
Уявімо ситуацію: ви створили сайт, наповнили його інформативним і цікавим текстом, однак, стратегія залучення споживача тільки текстом більше не працює, крім того,...